
Introductory video (5min)
Abstract
Different users find different images generated for the same prompt desirable. This gives rise to personalized image generation which involves creating images aligned with an individual’s visual preference. Current generative models are, however, tuned to produce outputs that appeal to a broad audience are unpersonalized. Using them to generate images aligned with individual users relies on iterative manual prompt engineering by the user which is inefficient and undesirable.
We propose to personalize the image generation process by, first, capturing the generic prefernces of the user in a one-time process by inviting them to comment on a small selection of images, explaining why they like or dislike each. Based on these comments, we infer a user’s structured liked and disliked visual attributes, i.e., their visual preference, using a large vision-language model. These attributes are used to guide a text-to-image model toward producing images that are tuned towards the individual user's visual preference. Through a series of user studies and large language model guided evaluations, we demonstrate that the proposed method results in generations that are well aligned with individual users' visual preferences.
More Visualization






How does it work?
We ask interested individuals to comment on a small set of images. These images are generated such that they have diverse styles and concepts. Note that the individuals' comments are not required to be of a specific structure. Thus, users can write as much or little as they like. Clearly, more detailed and expressive comments would lead to better personalization.
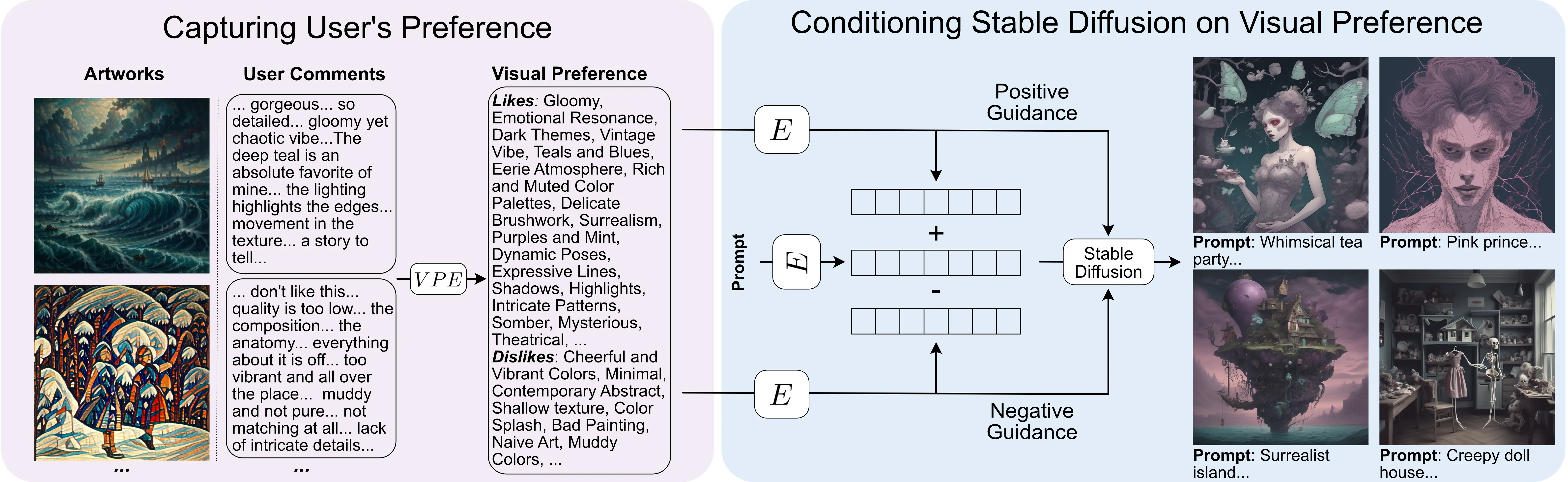
Our method allows for such free-form comments as we make use of a vision-language model to extract structured preferences, i.e. a visual preference extractor (VPE). To get the VPE, we fine-tune IDEFICS2-8B on a dataset of simulated agents and their comments and preferences. Converting the user’s free-form comments into structured visual preferences is a one-time process that provides us with a concise representation of the individual's preferences. The user’s visual preference are then encoded and added to the prompt embedding. They’re also used in the guidance formula directly to guide Stable Diffusion’s results toward the user’s preferences.

Moreover, we introduce a proxy metric for automatic evaluation. We fine-tune IDEFICS2-8B for this task, representing each individual by the sets of images they like. Given this set of images, the proxy metric assigns higher scores to query images that share the preferred visual attributes, and lower scores to those that do not.
Degree of Personalization
Our approach offers flexibility by letting users adjust the personalization level with a simple slider tool. See how personalization increases for one user gradually. As the personalization degree increases from 0 to 1, results become more tailored to user preferences, departing from generic outcomes while keeping the original prompt's intent.
Personalized Images for 10 Agents

BibTeX
@article{ViPer,
title={{ViPer}: Visual Personalization of Generative Models via Individual Preference Learning},
author={Sogand Salehi and Mahdi Shafiei and Teresa Yeo and Roman Bachmann and Amir Zamir},
journal={arXiv preprint arXiv:2407.17365},
year={2024},
}